Work Monitoring Tool
Comprehensive Tampermonkey script preventing SLA breaches and tracking scheduler availability through intelligent alerts, real-time monitoring, and automated management notifications across 500+ delivery station task queues
CROSS-REGIONAL IMPACT: Source code shared with North America Business Impact Analysis team for adaptation to their operational workflows
Performance at Risk
Management identified systematic SLA breaches affecting operational metrics across the EU network
Strict 1-Minute SLA
Schedulers log into the queue platform at shift start. When tasks land in the queue, they must be accepted within 1 minute maximum to meet SLA. Manual monitoring proved unreliable during high-volume periods when multiple tasks arrived simultaneously.
Multitasking Blindspots
Schedulers juggling multiple concurrent tasks require constant tab switching, station communication, and focus-intensive work. During these activities, new queue tasks went unnoticed—missing the 1-minute acceptance window or leaving tasks open too long, creating invisible SLA breaches.
No Early Warning System
Schedulers had no real-time alerts when approaching SLA deadlines. By the time management identified issues through post-shift metrics, performance was already impacted. No mechanism existed to flag at-risk tasks during active work.
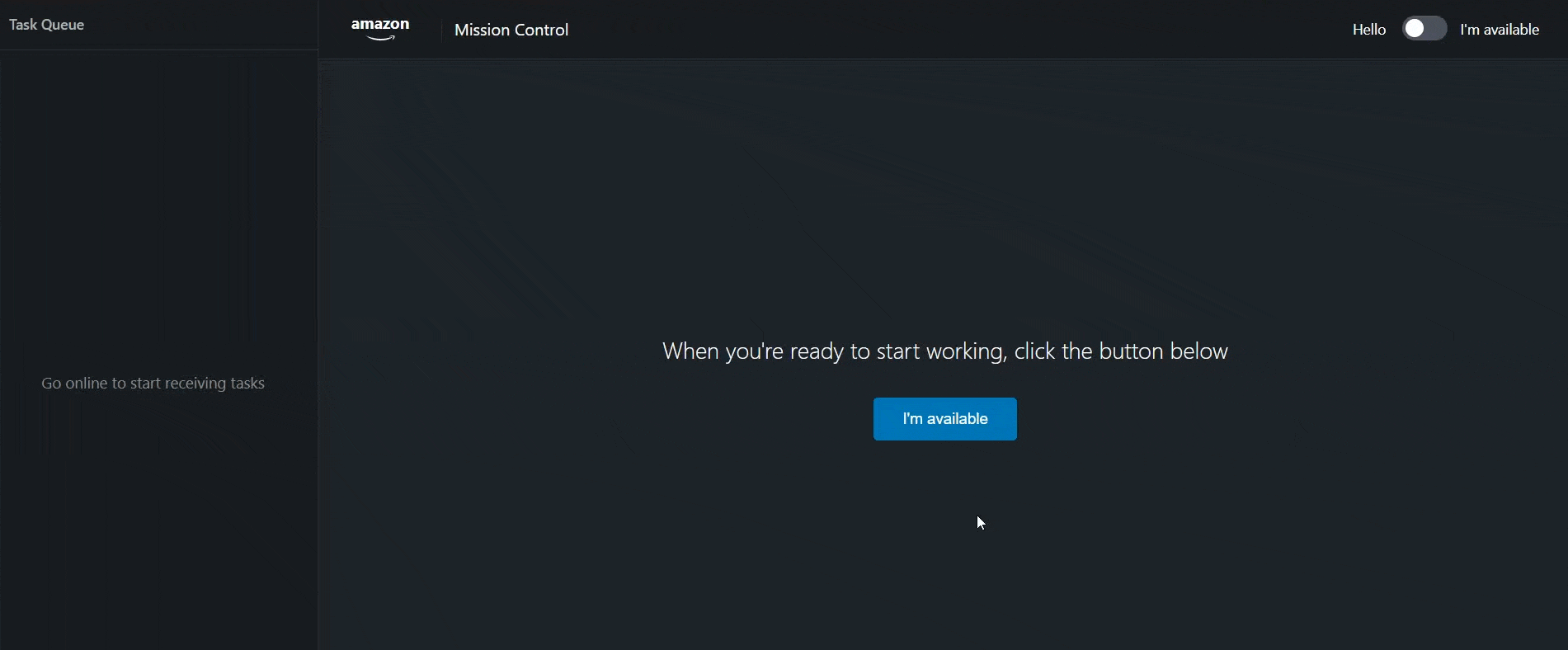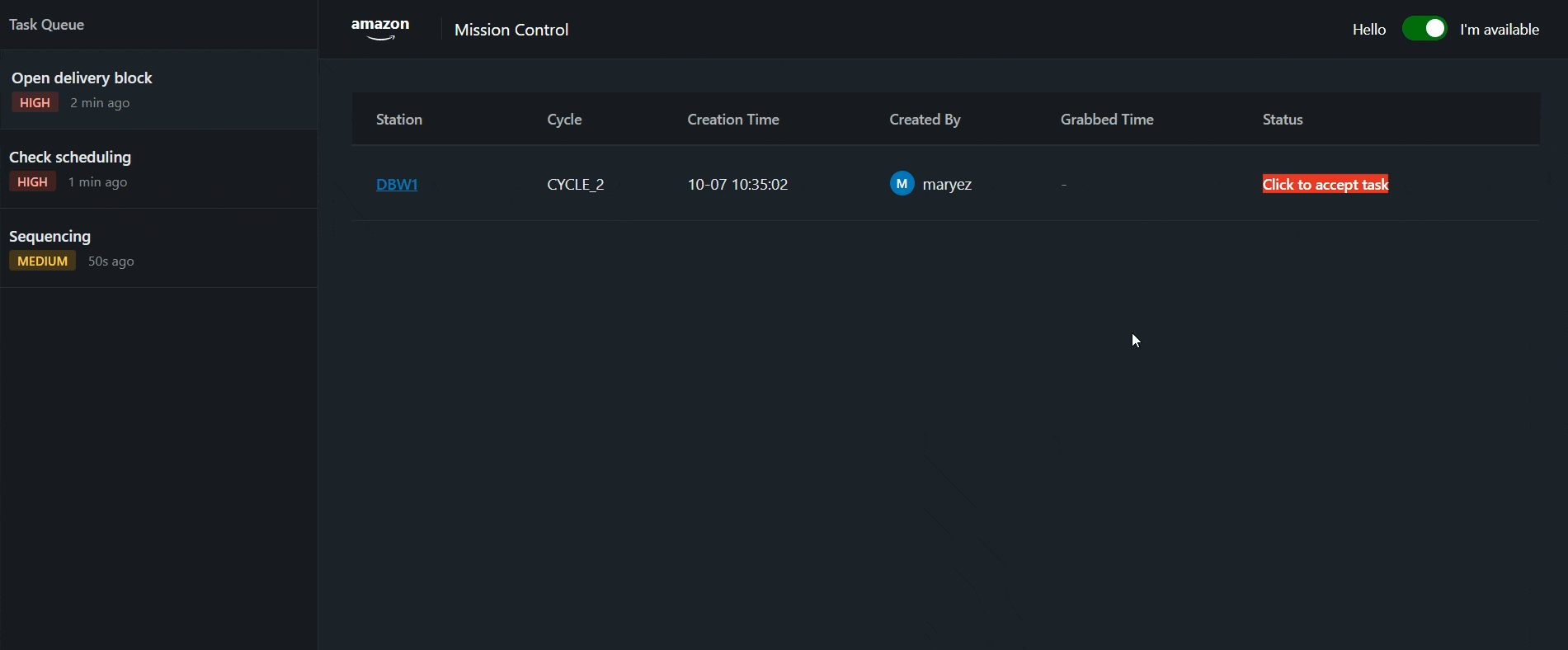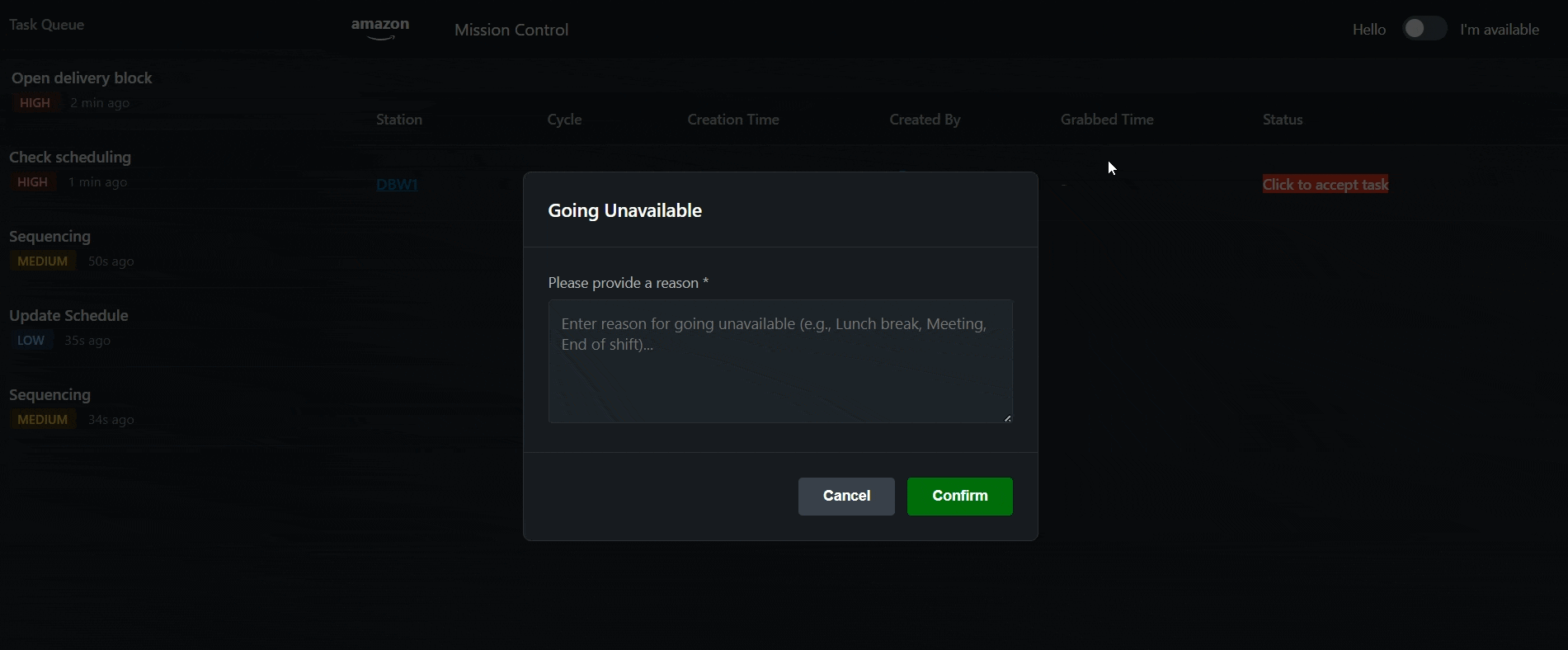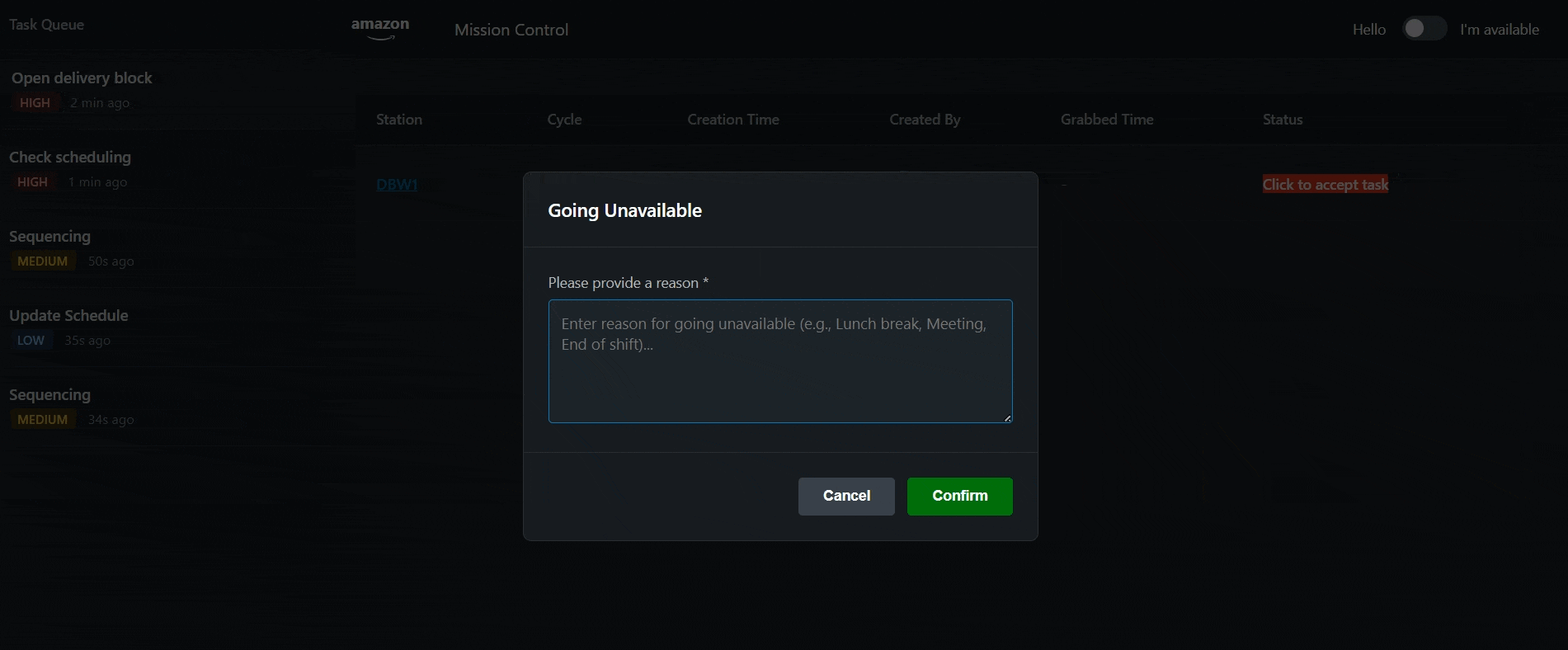
Scale & Visibility
With 500+ delivery stations and multiple schedulers working simultaneously, leadership could see unaccepted tasks—but couldn't identify which tasks were open for too long. When dozens of tasks flood the queue, it's impossible to distinguish whether a scheduler is dwelling on a task due to a real issue, actively working it, or if it's been missed entirely.
Untracked Offline Activity
When schedulers went offline, management had no visibility into why or for how long. No notification system existed—leadership had to manually scan who was offline and reach out individually to verify if it was a break, meeting, or other reason. This created gaps in capacity planning and made it impossible to distinguish between legitimate breaks and unexplained absences.
Guardian Protocol
Browser-based protection layer with dual notification system—immediate scheduler alerts and management escalation pathways
Real-Time Monitoring
Tampermonkey script continuously tracks task acceptance and completion times directly in the queue platform browser interface. Eliminates manual queue checking, reducing time on task by ~40%.
- Monitors 1-minute acceptance SLA automatically
- Tracks open task duration without manual checks
- Multi-level alert escalation
- Saves ~650h annually across network
Intelligent Alerts & Auto-Focus
Multi-layer notification system with automatic tab switching ensures schedulers never miss tasks, even when working in other applications. Schedulers can focus on actual work instead of constantly monitoring the queue.
- Instant notification + sound alert when task arrives
- Auto-switches to queue tab when approaching 1-min SLA
- Eliminates need for manual queue monitoring
- Audio warnings for extended open tasks
- Frees schedulers to focus on task execution
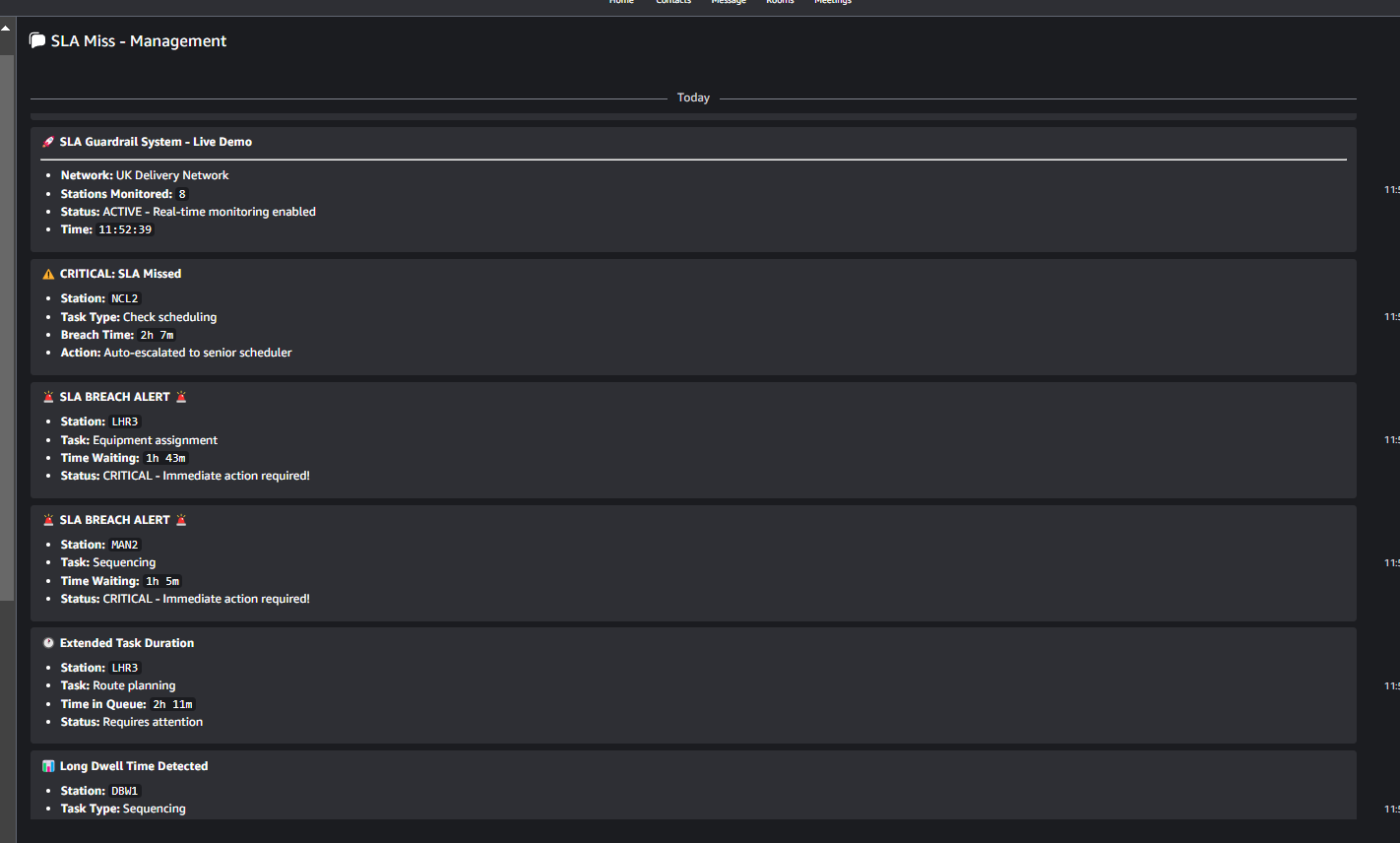
Management Dashboard
After initial success, implemented auto-reporting to dedicated room for leadership visibility and rapid intervention.
- Automatic reports to management room
- Unaccepted task alerts
- Overdue task notifications
- Real-time station-level insights
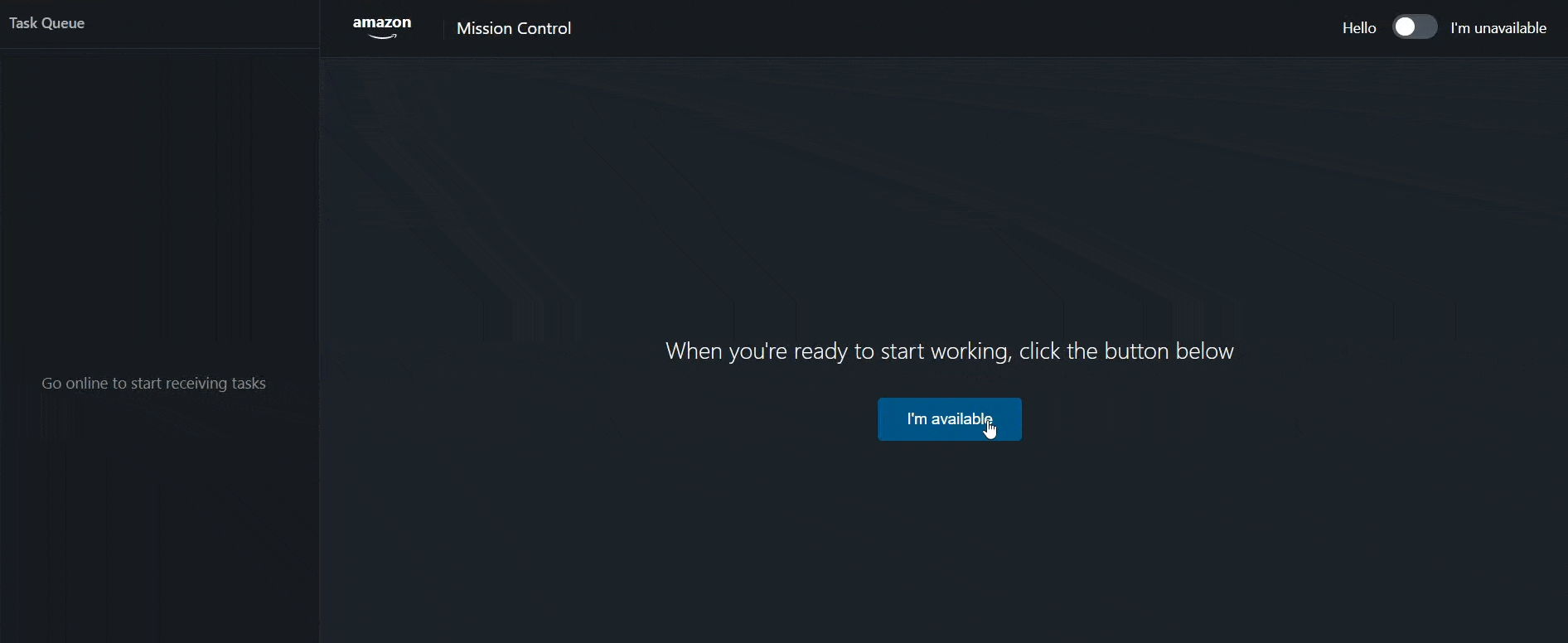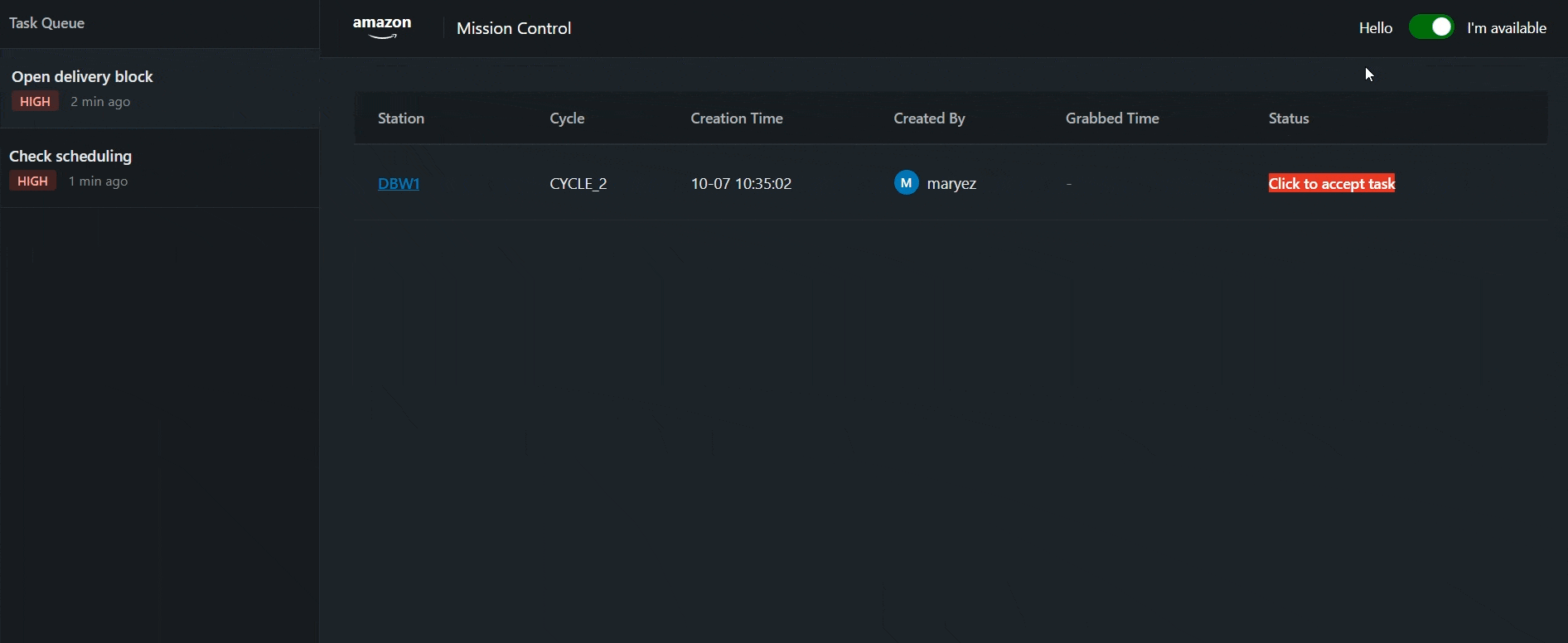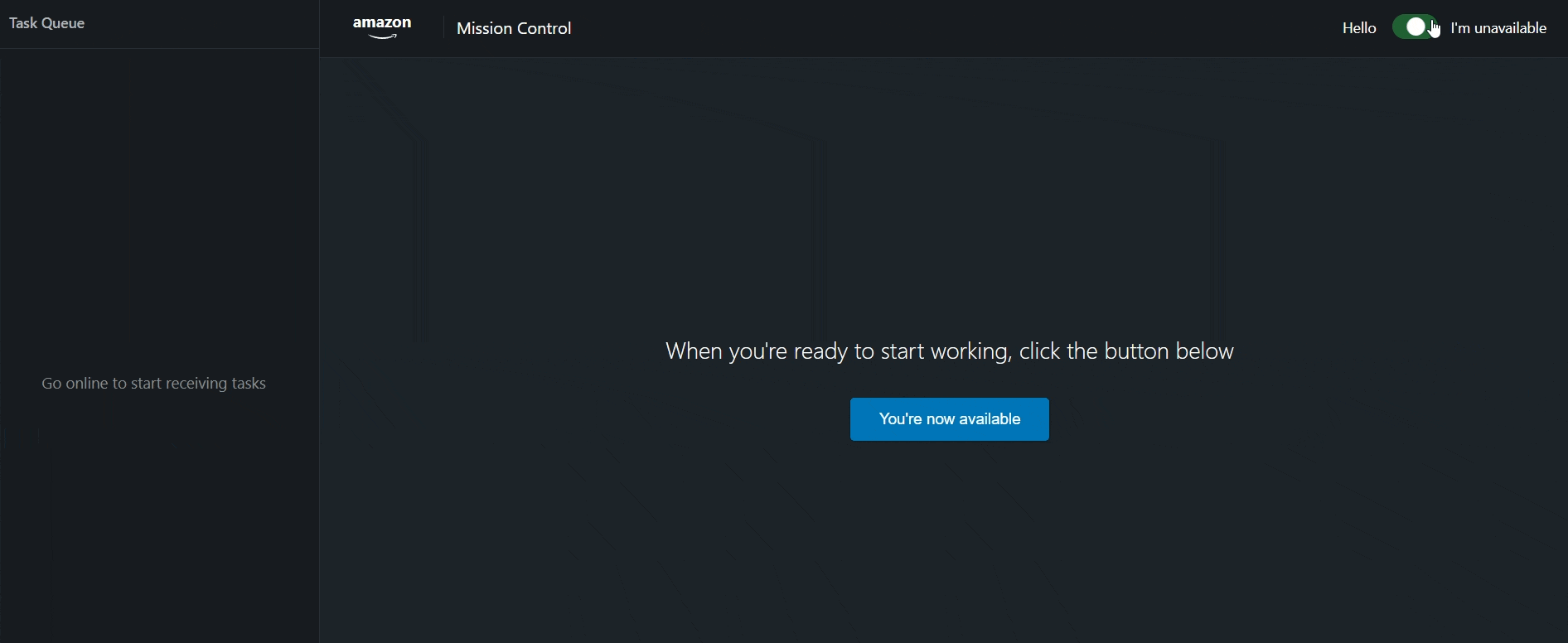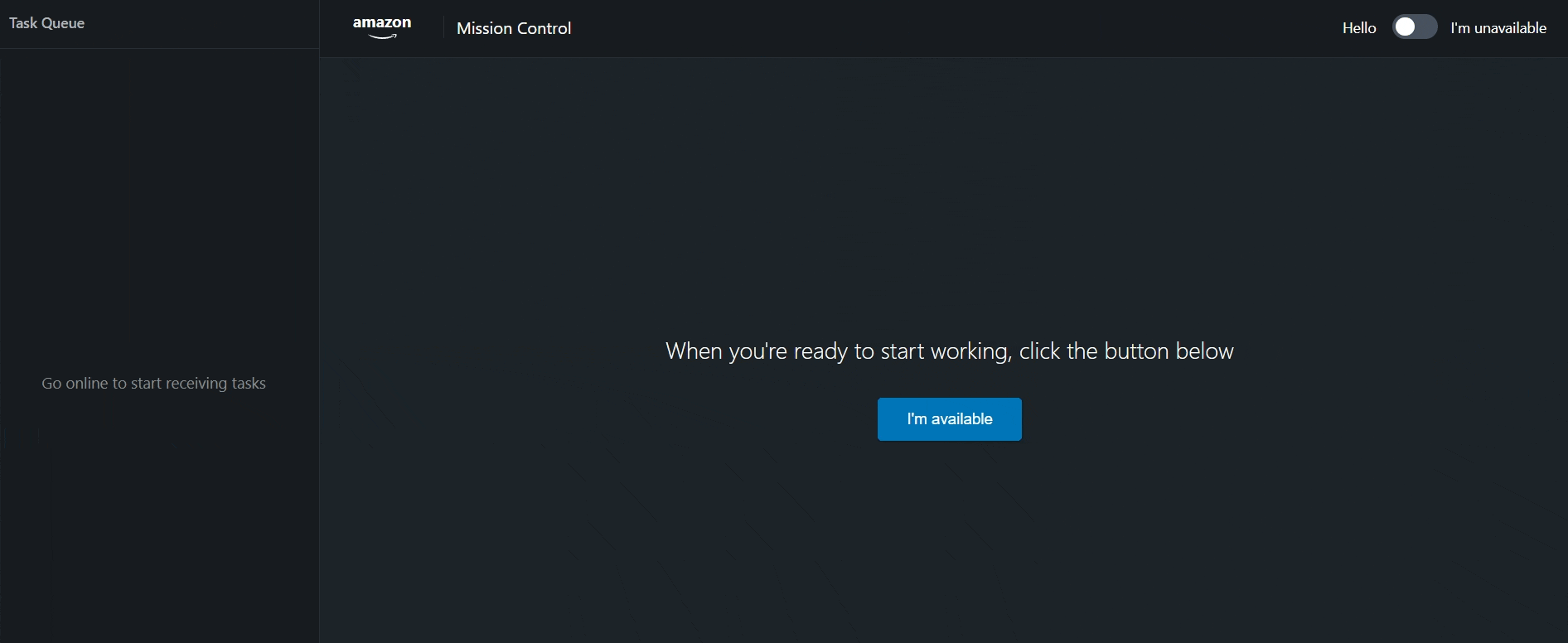
Offline Tracking & Notifications
Mandatory offline reason tracking with automatic management notifications. When schedulers go unavailable, they must enter a reason—eliminating manual verification and providing real-time visibility into team capacity.
- Required reason input when going offline
- Auto-notification to management room
- Eliminates manual verification calls
- Real-time capacity planning insights
- Audit trail of all offline periods
Mandatory Deployment
Adopted as mandatory installation before work sessions—transformed from individual tool to organizational standard.
- Easy Tampermonkey installation
- Automatic updates
- Required pre-shift setup
- Consistent protection across all users
Protection in Action
Complete workflow visualization—from scheduler alerts to management oversight
Task Monitoring in Action
Task Webhook Integration
Before & After Implementation
Transforming offline activity from invisible gaps to tracked, notified events
Silent Offline Events
Required Offline Justification
Automated Offline Alerts

Evolution & Impact
Management Escalation
Leadership outlined systematic SLA breach patterns affecting team performance metrics. Proactively volunteered to develop browser-based solution requiring zero infrastructure changes.
Script Design & Deployment
Engineered Tampermonkey script with real-time task monitoring and multi-level alert system. Tested across queue platform and deployed to scheduler team.
Immediate Impact
First month post-launch demonstrated measurable reduction in SLA misses. Script adopted as standard framework—required installation before shift start.
Management Reporting Layer
Enhanced script with auto-reporting to dedicated management room. Real-time visibility enabled rapid intervention across 500+ delivery stations, replacing manual queue searches.
Mandatory Offline Notifications
Added mandatory reason modal when schedulers go offline, with automatic webhook notifications to management. Eliminated manual verification calls and provided real-time capacity visibility—transforming invisible offline periods into tracked, justified events.
Long-Term Performance Gains
Ongoing deployment showed continued SLA improvement, significant reduction in time-on-task metrics, and complete visibility into team availability. Work monitoring tool became critical operational standard across the network.
Source Code Shared with North America Business Impact Analysis Team
After demonstrating measurable impact across EU operations, shared complete source code with North America Business Impact Analysis team to adapt for their operational scenarios
KNOWLEDGE TRANSFER: Following successful deployment and sustained performance improvements in EU operations, the North America Business Impact Analysis team requested access to the source code. Provided complete codebase with documentation to enable adaptation for their specific workflows and operational requirements.
CROSS-REGIONAL IMPACT: This collaboration allowed the North America Business Impact Analysis team to leverage proven monitoring architecture while customizing alert thresholds, notification systems, and integration points to match their unique operational environment—demonstrating the tool's flexibility and cross-functional applicability.