How It Works
Automated offset calculation integrated into daily scheduling operations
Download Roster & Manifest Data
Scheduler downloads driver roster, sequencing output showing total routes and shipments, and complete manifest file for the cycle. Selects which cycle they're planning (primarily evening cycles during pilot phase).
Automated Offset Calculation
Tool analyzes pre-scheduled driver count versus routes needing coverage. Uses historical 30-day no-show patterns to calculate optimal buffer. Outputs exact number: "Open X additional blocks on top of pre-scheduled capacity." This happens automatically—no manual calculation needed.
Proactive Block Opening
Scheduler applies recommended offset BEFORE departure time, avoiding the problems of blocks opened too close to dispatch (low acceptance rates) or inability to reopen for later time. Blocks are opened with enough buffer that drivers can accept them. No more reactive firefighting.
Team Capacity Freed Up
Instead of constant requests to our team for emergency block openings, the process is handled proactively. Team saw 30-40% reduction in no-show related escalations. Time previously spent on reactive requests now available for strategic work and network optimization.
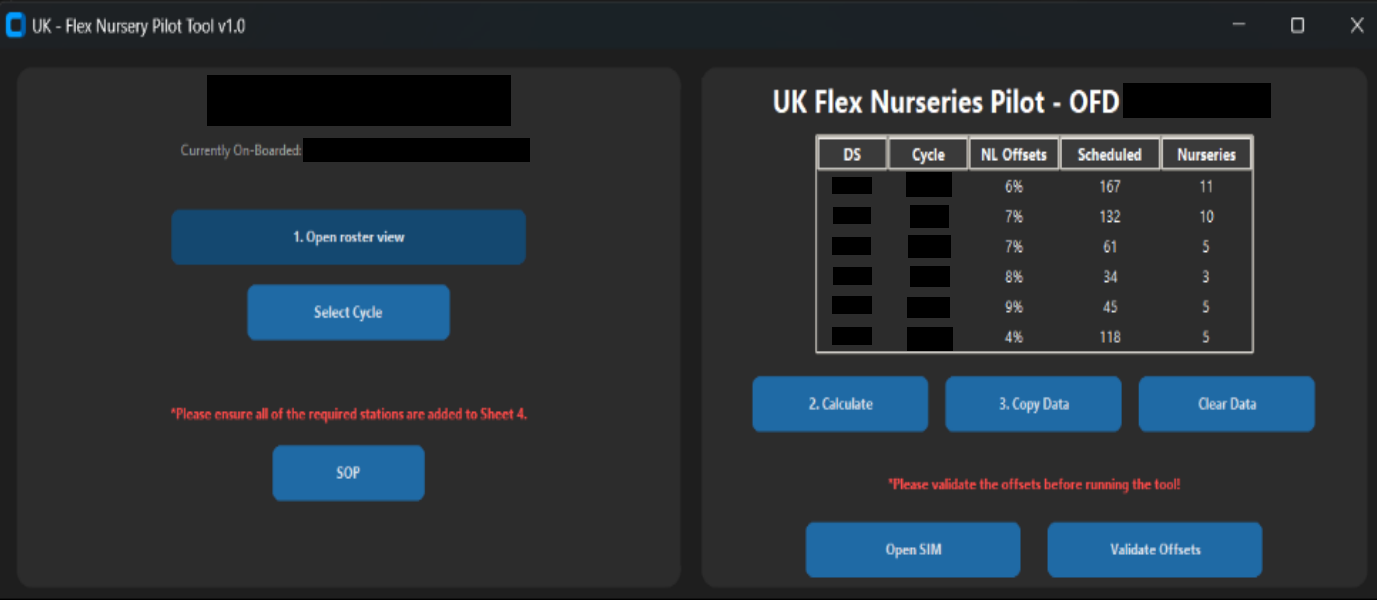
Note: Interface shown is the first version developed during pilot phase, no longer in active use. Displayed for demonstration purposes only.
Department-Wide Impact & Measurement
~9,000 Hours Saved Annually
I identified the no-show problem, proposed this solution, and gained management sponsorship and approval. Management tracked department-wide workload reduction through analytical dashboards measuring task assignments and escalation request categories by station. Data collection showed the no-show request category—which represented the majority of our scheduler workload—significantly decreased following deployment of this new process and tool.
The ~9,000 hours annual savings figure is based on management's operational data analysis comparing before/after task volumes across the scheduler department. This represents time previously spent on reactive no-show crisis management that was eliminated through the proactive capacity planning process I designed and built.
Critical Impact: Hours saved were not eliminated positions—they were reallocated to other high-value tasks and responsibilities. This efficiency gain enabled the department to expand operational scope and take on additional network optimization initiatives without requiring additional headcount, demonstrating measurable productivity improvement.
My Contributions & Cross-Team Collaboration
I originated the idea, designed the capacity planning process, and built the complete tool (calculation engine + UI). Analytics team conducted historical data analysis and provided configuration parameters based on their findings. Tech team's role was strictly providing database access following security best practices and advisory support when requested—all process design, business logic, and tool development was my work.
Following successful pilot validation, ownership was transitioned to the central Analytics team for UK-wide rollout and ongoing optimization as part of broader operational planning infrastructure.